Matriz de Confusion en el Aprendizaje Supervisado
La matriz de confusión es una herramienta utilizada en el aprendizaje supervisado, que es una rama del aprendizaje automático, para evaluar el rendimiento de un modelo de clasificación. Esta matriz muestra la calidad de las predicciones realizadas por un modelo en comparación con los valores reales de las etiquetas de clase.
En una matriz de confusión, las predicciones del modelo se dividen en cuatro categorías diferentes:
- Verdaderos positivos (TP): Representa los casos en los que el modelo predijo correctamente que una instancia pertenece a una clase específica.
- Verdaderos negativos (TN): Representa los casos en los que el modelo predijo correctamente que una instancia no pertenece a una clase específica.
- Falsos positivos (FP): Representa los casos en los que el modelo predijo incorrectamente que una instancia pertenece a una clase específica cuando en realidad no lo hace.
- Falsos negativos (FN): Representa los casos en los que el modelo predijo incorrectamente que una instancia no pertenece a una clase específica cuando en realidad sí lo hace.
La matriz de confusión se organiza de la siguiente manera:

En base a los valores en esta matriz, se pueden calcular diversas métricas de evaluación del rendimiento del modelo, como la precisión, la sensibilidad (también conocida como recall), la especificidad y la puntuación F1, entre otras. Estas métricas proporcionan una comprensión más completa de cómo el modelo está realizando la clasificación en diferentes escenarios.
Una matriz mas real usando weka:
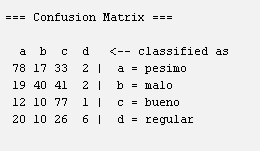
la matriz de confusión es una herramienta esencial para analizar y comprender el rendimiento de un modelo de clasificación en el aprendizaje supervisado, permitiendo tomar decisiones informadas sobre cómo ajustar o mejorar el modelo.
Entradas relacionadas



Sobre el Autor
Jose Luis Bugarin
Pragmático, soy de leer y hacer y no esta demás mencionar que las opiniones son mías :) #telodijoelbuga