Matriz de Confusión | Efectividad del Modelo de Clasificación
Una matriz de confusión describe el rendimiento del modelo de clasificación. En otras palabras, la matriz de confusión es una forma de resumir el rendimiento del clasificador.

En la siguiente grafica, tenemos la apariencia y los elementos de una matriz de confusión:
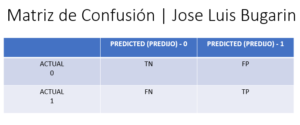
En donde:
TN (True negative): Este es el recuento de resultados que originalmente fueron negativos y se predijeron negativos.
FP (falso positivo): Este es el recuento de resultados que fueron originalmente negativos pero que se predijeron positivos. Este error también se denomina error de tipo 1
FN (Falso negativo): Este es el recuento de resultados que fueron originalmente positivos pero se predijeron negativos. Este error también se denomina error de tipo 2.
TP (verdadero positivo): Este es el recuento de resultados que fueron originalmente positivos y se predijeron como positivos.
El objetivo de todos los algoritmos de aprendizaje automático (machine learning) y aprendizaje profundo(deep learning) es maximizar TN y TP y minimizar FN y FP.
Entradas relacionadas



Sobre el Autor
Jose Luis Bugarin
Pragmático, soy de leer y hacer y no esta demás mencionar que las opiniones son mías :) #telodijoelbuga